Abstractions
My previous post referenced the short film Powers of Ten which zooms out to galatic scales then down to sub-atomic particles. While the pace was quick it was glacial compared to how fast we can jump around with our thoughts. We can consider an atom, a ham sandwich, and a galaxy within two seconds. How can we move around so effortlessly?
Abstraction is a tool of thought. Abstraction is the process of ignoring some details in order to focus on others. We do this all the time. It is our main weapon against the complexity of the world. We jump from one abstraction to another depending on our immediate needs.
When I turn the key of my car in the morning, I am not thinking about the chemical reactions in the battery or the details of the combustion cycle. I just turn the key and listen for the sound of the car starting. This is my mental model of the car: you turn the key and the engine makes a starting sound. Now suppose the car doesn’t start, I hear only a click. Then I adopt new abstractions. I start thinking about the electrical system, the starter, the battery.
One of the most persistent and convincing illusions which we enjoy is that of a continuous high resolution visual field. In reality we only see “high resolution” over an area about the size of a quarter held at arms length. This is our fovea and it is only 1% of the retinal area but maps to 50% of the visual cortex. That is, your brain is overwhelmingly occupied with this tiny portion of your view.

Suppose you are at a scenic overlook. You feel like you are seeing the full splendor and detail of the scene all at once. Instead your eyes are actually darting around from one detail to the next; you assemble the full panorama only in your mind. You can witness this phenomenon by staring at a single word in this text. Now without moving your eyes try to see a word a few words away. If you can hold your eyes still you should find it very difficult to resolve details in these nearby words.
I believe abstraction works much like the visual system. We can think about complex objects like cars, but the details are mostly abstracted away at any point in time. Research has found that we can usually hold only 5-9 items in short term memory. I think abstractions tend to have about that many concrete details. When we need to consider something else, we quickly shift to a new abstraction to bring the necessary details to the forefront.
Writing software is all about creating and managing hierarchies of abstractions. In the real world as you dive down into subparts of objects you eventually hit bottom, quarks or something we do not know how to subdivide. In software there is no such limit. In theory you can pile abstractions to the moon. In practice however there are limits. Large software systems are notoriously hard to write and prone to errors.
Joel Spolsky a software developer and blogger has written about The Law of Leaky Abstractions. His claim is that all non-trivial abstractions “leak”. The abstraction advertises that certain details are private, that you can ignore them, but those details actually do matter and cause problems.
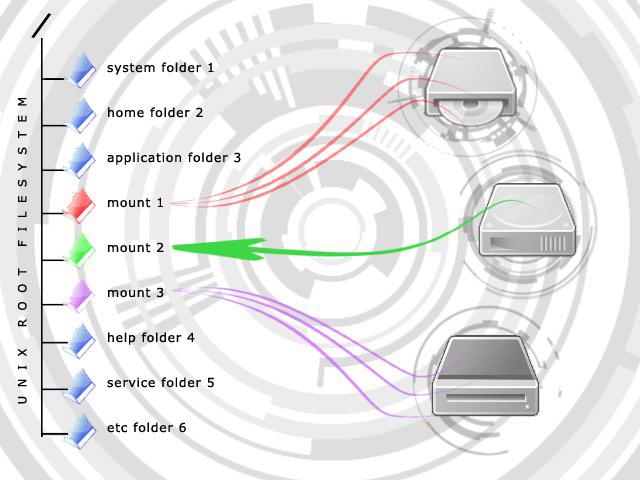
One of his examples is the “remote filesystem”. Your filesystem is a software layer that deals with files on disk, like those sitting on your hard drive. However sometimes files are not local, they are located across internet. Generally the approach is to hide this “detail” from the programmer. If you want to open a file it works identically wherever the file actually is. This approach can backfire. As Joel says the abstraction leaks because the location of the file really does matter.
Joel suggests there is no real solution to deal with these leaky abstractions, that dealing with them is just what makes programming hard work. I think he is mostly right, but I think there is a general way we can sometimes combat the problem. Remember abstraction happens in the mind of the observer. A software layer might suggest a particular abstraction, but it does not impose one. Instead, the person writing code is free to invent their own more productive abstractions.
Most filesystem interfaces are agnostic about how long operations should take. Any details about timing are abstracted away. But the code using the filesystem could time each operation itself and draw conclusions about the underlying physical setup. For example, if operations are taking only milliseconds it behaves one way but if they are taking multiple seconds it swaps in a completely abstraction, one where it considers every filesystem operation to be expensive and minimizes them.
In general I think the solution to leaky abstractions is more abstractions. We should not rigidly buy into whatever abstraction is implied by lower level code. We have to invent more and different abstractions of our own and fluidly switch among them, just like we do when thinking.